Why random rotations are good for RoPE
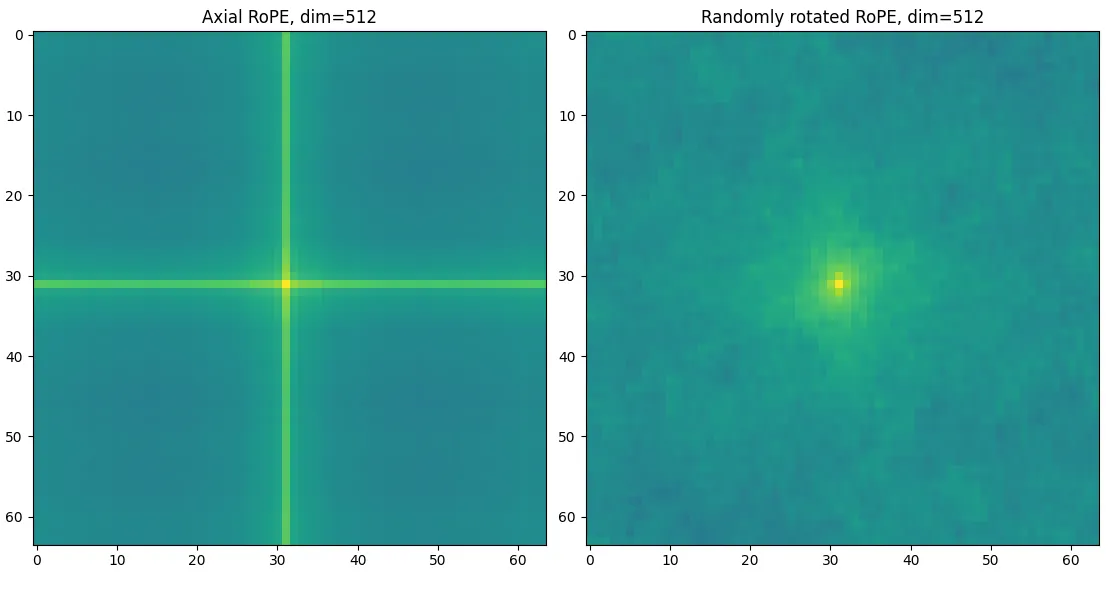
Jerry Xiong created the above picture, which started these findings. With axial RoPE (Rotary Positional Embedding), positionally attending to a single pixel causes incidental attention to a cross, because RoPE’s sine waves align. This is well-known. But he discovered that with random RoPE rotations, the cross disappears.
Random-rotation RoPE is better than your current 2D axial RoPE, and Jerry’s blog post has an even better version. Jerry’s preferred explanation is that covering angles uniformly is the goal.
However, my preferred explanation is that incoherent angles are the goal. So this blog post is an appendix, describing an optimality condition for RoPE, the math behind this RoPE variant, and where incoherence arises.
Focus on a single token
When comparing the attention operation to other architectures, the main talent of attention is its ability to attend to single keys (needle-in-a-haystack retrieval). If you disagree, then either your understanding of ML architecture is poor, or you know too much mechinterp.
Accordingly, the optimal RoPE should positionally focus on a single token. Let’s work out the math.
Notate the center of an image as complex , which RoPE is attending to. With as indices, let each complex RoPE term be , where is the angle and is the frequency’s magnitude. The attention score at a point is , where the dot is the real-plane dot product, considering the complex plane as .
If is the canvas, then the total positional energy of attention is its squared value, integrated over the canvas: , with . The distance-adjusted energy is ; it is the same thing multiplied by . The ideal RoPE minimizes , representing that attention is focused at the point .
The frequencies are fixed, being used to control specificity and range.1
So we can only pick the angles .
At , the attention score is . This represents concentrated attention. Our goal is to minimize energy away from the center, to make small. In the absence of a cancellation trick, the next best tool is to make attention behave like noise - so that different terms do not line up except by chance.
At points away from the center, random-rotation RoPE evaluates each channel at a position uncorrelated with other RoPE channels. The average of uncorrelated values behaves like noise, scaling as , while the average value at the center remains . So as increases, attention can better focus on the center. Compared to axial RoPE, the stray attention on the cross doesn’t move elsewhere - it is erased.
For non-random rotations, the first guess is to set to multiples of the golden ratio. Two rotations overlapping would mean for integers , leading to . By Hurwitz’s theorem, the golden ratio is the hardest number to approximate by rationals, so it’s good at avoiding overlaps. This produces Golden Gate RoPE in Jerry’s blog post, where the incorrect multiple of 2 is my fault.
But the golden ratio neglects that our frequencies are exponentially increasing - interactions between adjacent frequencies are the strongest ones. As the separation between frequencies increases, we expect the difference between rotation angles to transition incompletely from toward , because perpendicular angles are the most uncorrelated. And the highest and lowest frequencies will have rotations that are only surrounded on one side, not two, so they will also need special logic.
These issues are fiddly and have local minima, so let’s pretend we have infinite channels.
Suppose the frequencies are exponentially distributed as . Minimize the energy inside the annulus . This captures a slice of RoPE frequencies; the total energy away from is a concatenation of such annuluses. Truncate the frequencies to for numerical convenience.
Here, is measured when .
Observations
At high , broad regions of angles perform comparably. This is because the higher separation between frequencies causes them to interact less.
Random rotations are not as good as chosen ones, but are better than axial RoPE. Beware that the truncation to means it’s easy to overfit. The optimal angle trends toward with higher , but it’s unclear if this visualization is accurate enough to count as evidence for this effect.
The closer is to 1, the more important it is to choose a good angle.
The failure of axial RoPE (angle or ) is caused by having high energy in a line - which fails to decay away from the origin. This is the penalty of correlated sine waves.
In practice, I don’t expect anyone to care enough to optimize more than the single angle. will do fine for the lazy.
Credit
Claude Code did the visualizations. To discuss this article, I’m in the EleutherAI discord.
Jerry’s blog post cites prior works such as RoPE-Mixed, but despite the similarities in final method, his discovery does not descend from them. His random-rotation picture, in which incoherence can be recognized, deserves most of the credit, a la Rosalind Franklin.
nor wrote a third post, on N-dimensional RoPE.
Footnotes
-
Partial RoPE (
rotary_dim) originated in the pre-Tri Dao days when RoPE was costly, so people rotated only part of the head. Nowadays, partial RoPE is no longer a speedup, though FlashRotary still supports it. My suggestion is to change the low frequencies instead of using partial RoPE. ↩